HTTP 완벽 가이드 [1-4] - 커넥션 관리
by Yurim Koo
‘HTTP 완벽가이드’ 책의 내용을 요약 정리한 시리즈입니다.
(사진 출처: 인터넷 교보문고)

HTTP 시리즈
- HTTP 완벽 가이드 [1-1] - HTTP 개관
- HTTP 완벽 가이드 [1-2] - URL과 리소스
- HTTP 완벽 가이드 [1-3] - HTTP 메시지 - (1)
- HTTP 완벽 가이드 [1-3] - HTTP 메시지 - (2)
- HTTP 완벽 가이드 [1-4] - 커넥션 관리
1부. HTTP: 웹의 기초
4장. 커넥션 관리
4.1 TCP 커넥션
- 모든 HTTP 통신은 패킷 교환 네트워크 프로토콜의 계층화된 집합인 TCP/IP를 통해 이루어짐
- 일단 커넥션이 맺어지면 클라이언트-서버 간의 주고 받는 메시지는 손실되거나 순서가 바뀌지 않고 안전하게 전달
- 웹브라우저가 TCP 커넥션을 통해 웹 서버에 요청보내는 순서
1) 브라우저가 호스트명을 추출
2) 브라우저가 이 호스트명에 대한 IP 주소를 찾음
3) 브라우저가 포트 번호를 얻음
4) 브라우저가 IP 주소의 포트로 TCP 커넥션을 생성
5) 브라우저가 서버로 HTTP 요청 메시지를 보냄
6) 브라우저가 서버에서 온 HTTP 응답 메시지를 읽음
7) 브라우저가 커넥션을 끊음
1) 신뢰할 수 있는 데이터 전송 통로인 TCP
- TCP는 충돌 없이 순서에 맞게 HTTP 데이터를 전달
2) TCP 스트림은 세그먼트로 나뉘어 IP 패킷을 통해 전송된다
- TCP는 IP 패킷(=IP 데이터그램)이라고 불리는 작은 조각을 통해 데이터 전송
- 세그먼트라는 단위로 데이터 스트림을 잘게 나누고, 세그먼트를 IP 패킷이라고 불리는 봉투에 담아 인터넷을 통해 데이터를 전달
- 이 모든 것은 TCP/IP 소프트웨어에 의해 처리되며, 그 과정은 HTTP 프로그래머에게 보이지 않음
- 각 TCP 세그먼트는 하나의 IP 주소에서 다른 IP 주소로 IP 패킷에 담겨 전달; IP 패킷의 구성은 아래와 같음
- IP 패킷 헤더 (보통 20바이트): 발신지, 목적지 IP 주소, 크기, 기타 플래그
- TCP 세그먼트 헤더 (보통 20바이트): TCP 포트 번호, TCP 제어 플래그, 데이터 순서와 무결성 검사를 위해 사용되는 숫자 값
- TCP 데이터 조각 (0 혹은 그 이상의 바이트)
3) TCP 커넥션 유지하기
- TCP는 포트 번호를 통해 여러 개의 TCP 커넥션 유지
- TCP 커텍션은 네 가지 값으로 식별
<발신지 IP 주소, 발신지 포트, 수신지 IP 주소, 수신지 포트> - 서로 다른 두 개의 커넥션은 네 가지 주소 구성요소 값이 모두 같을 수 없음 (일부는 가능))
4) TCP 소켓 프로그래밍
- 소켓 API는 HTTP 프로그래머에게 TCP/IP 세부사항을 숨김
- 소켓 API를 사용하면, TCP 종단(endpoint) 데이터 구조를 생성하고, 원격 서버의 TCP 종단에 그 종단 데이터 구조를 연결하여 데이터 스트림을 읽고 쓸 수 있음
- 소켓 API는 기본적인 네트워크 프로토콜의 핸드셰이킹, TCP 데이터 스트림과 IP 패킷 간의 분할 및 재조립에 대한 모든 세부사항을 외부로부터 숨김
4.2 TCP 성능에 대한 고려
- HTTP는 TCP 바로 위의 계층이기 때문에 HTTP 트랜잭션의 성능은 아래 계층인 TCP 성능에 영향을 받음
- 그러므로 TCP 성능에 대한 고려를 통한 HTTP 커넥션 최적화가 필요함
1) HTTP 트랜잭션 지연
- 클라이언트나 서버가 너무 많은 데이터를 내려받거나 복잡하고 동적인 자원을 실행하지 않는 한, 대부분의 HTTP 지연은 TCP 네트워크 지연 때문에 발생
- 요청 메시지가 인터넷을 통해 전달되고 서버에 의해 처리되는 시간
- 웹 서버가 HTTP 응답을 보내는 시간 등
2) 성능 관련 중요 요소
- 고성능의 HTTP 소프트웨어를 개발하고 있다면, 아래 항목을 각각 이해해야 하지만 그 정도의 성능 최적화를 할 게 아니라면 건너뛰어도 좋음
- TCP 커넥션의 핸드셰이크 설정
- 인터넷 혼잡을 제어하기 위한 TCP의 느린 시작 (slow-start)
- 데이터를 한데 모아 한 번에 전송하기 위한 네이글(nagle) 알고리즘
- TCP의 편승(piggyback) 확인응답(acknowledgment)을 위한 확인 응답 지연 알고리즘
- TIME_WAIT 지연과 포트 고갈
4.3 HTTP 커넥션 관리
1) 흔히 잘못 이해하는 커넥션 헤더
- 두 개의 인접한 HTTP 애플리케이션이 현재 맺고 있는 커넥션에만 적용될 옵션을 지정해야 할 때가 있음
- HTTP 커넥션 헤더 필드는 커넥션 토큰을 쉼표로 구분하고 있으며, 그 값들은 다른 커넥션에 전달되지 않음
- 커넥션 헤더에는 다음 세 가지 종류의 토큰이 전달될 수 있음
- HTTP 헤더 필드명은, 이 커넥션에만 해당되는 헤더들을 나열; 다음 커넥션에 전달하면 안 됨 -> 삭제
- 임시적인 토큰 값은, 커넥션에 대한 비표준옵션을 의미
- close 값은, 커넥션이 작업이 완료되면 종료되어야 함을 의미
2) 순차적인 트랜잭션 처리에 의한 지연
- 커넥션 관리가 제대로 이루어지지 않으면 TCP 성능이 매우 나빠질 수 있음
- 순차적인 처리로 인한 물리적인 지연 + 하나의 데이터를 내려받는 중에는 웹페이지에 아무런 변화가 없어서 느끼는 심리적인 지연
- 예를 들어, 3개의 이미지가 있는 웹페이지가 있고 브라우저가 이를 보여주려면 네 개의 HTTP 트랜잭션을 만들어야 함. 하나는 해당 HTML을 받기 위해, 나머지 세 개는 첨부된 이미지를 받기 위한 것임. 각 트랜잭션이 새로운 커넥션을 필요로 한다면, 커넥션을 맺는데 발생하는 지연과 함께 느린 시작 지연이 발생할 것.
4.4 병렬 커넥션
- 여러 개의 TCP 커넥션을 통한 동시 HTTP 요청
1) 병렬 커넥션은 페이지를 더 빠르게 내려받는다
- 단일 커넥션의 대역폭 제한과 커넥션이 동작하고 있지 않은 시간을 활용하면, 객체가 여러 개 있는 웹페이지를 더 빠르게 내려받을 수 있을 것
- 다수의 트랜잭션 발생시, 별도의 커넥션에서 동시에 처리되어 총 지연시간이 줄어듦
2) 병렬 커넥션이 항상 더 빠르지는 않다
- 일반적으로 더 빠르지만, 항상 그렇지는 않음
- 클라이언트 네트워크 대역폭이 좁을 때, 제한된 대역폭 내에서 여러 개의 커넥션을 생성하며 생기는 부하 때문에 순차적으로 내려받는 것보다 더 오래 걸릴 수 있음
3) 병렬 커넥션은 더 빠르게 ‘느껴질 수’ 있다
- 병렬 커넥션이 페이지를 항상 더 빠르게 로드하지는 않으나, 화면에 여러 개의 객체가 동시에 보이면서 내려받고 있는 상황을 볼 수 있기 때문에 사용자는 더 빠르다고 느낌
- 사람들은 총 다운로드 시간이 더 많이 걸린다 하더라도 눈으로 작업을 확인할 수 있으면 더 빠르다고 여김
4.5 지속 커넥션
- 웹 클라이언트는 보통 같은 사이트에 여러 개의 커넥션을 맺음: 사이트 지역성(site locality)
- 따라서 트랜잭션 처리가 완료된 후에도 TCP 커넥션을 유지하여 앞으로 있을 HTTP 요청에 재사용할 수 있음: 지속 커넥션
- 커넥션 맺기 위한 준비작업 시간 절약
- 느린 시작으로 인한 지연 회피
1) 지속 커넥션 vs 병렬 커넥션
- 병렬 커넥션의 단점
- 각 트랜잭션마다 새로운 커넥션을 맺고 끊기 때문에 시간과 대역폭이 소요
- 각각의 새로운 커넥션은 TCP 느린 시작으로 인해 성능이 떨어짐
- 실제로 연결할 수 있는 병렬 커넥션의 수에 제한이 있음
- 지속 커넥션의 장점
- 커넥션을 맺기 위한 사전 작업과 지연을 줄여줌
- 튜닝된 커넥션을 유지하며 커넥션의 수를 줄여줌
- 지속 커넥션의 단점
- 지속 커넥션을 잘못 관리할 경우, 계속 연결된 상태로 수많은 커넥션이 쌓이게 될 것
- 이는 로컬의 리소스, 원격의 클라이언트와 서버의 리소스에 불필요한 소모를 발생시킴
- 따라서, 지속 커넥션은 병렬 커넥션과 함께 사용할 때 가장 효과적
2) HTTP/1.0+의 Keep-Alive 커넥션
- 커넥션을 맺고 끊는 데 필요한 작업이 없어서 작업 시간이 단축
- TCP 느린 시작이 일어나지 않기 때문에 요청 및 응답 시간 단축
- 요청에
Connection:Keep-Alive헤더 포함해야 함- 응답에
Connection:Keep-Alive헤더가 없으면, 서버가 keep-alive를 지원하지 않으며, 응답 메시지가 전송되고 나면 서버 커넥션을 끊을 것이라 추정할 수 있음
- 응답에
- Keep-Alive 헤더는 커넥션 유지를 바라는 요청일 뿐. 무조건 따를 필요는 없음; 언제든 keep-alive 커넥션을 끊을 수 있고, 처리되는 트랜잭션의 수를 제한할 수도 있음
timeout: 응답 헤더. 커넥션이 얼마간 유지될 것인지 의미 (동작 보장성은 없음)max: 응답 헤더. 몇 개의 HTTP 트랜잭션을 처리할 때까지 유지될 것인가를 의미- 위 파라미터들은
Connection:Keep-Alive헤더가 있을 때만 사용 가능
Keep-Alive와 멍청한(dumb) 프락시
- Connection 헤더의 무조건 전달
- 프락시는 Connection 헤더를 이해하지 못해서 해당 헤더를 삭제하지 않고 요청 그대로를 다음 프락시에 전달
- 프락시는 keep-alive를 전혀 모르지만, 받았던 모든 데이터를 그대로 클라이언트에게 전달하고 나서 서버가 커넥션 끊기를 기다림. 그러나 서버는 프락시가 커넥션을 유지하길 요청한 것으로 알고 있기 때문에 커넥션을 끊지 않음. 따라서 프락시는 커넥션이 끊어지기 전까지 무작정 기다리게 됨.
- 이런 잘못된 통신 때문에 브라우저는 타임아웃이 나서 커넥션이 끊길 때까지 기다림
- 이런 종류의 잘못된 통신을 피하려면, 프락시는
Connection헤더들을 절대 전달하면 안 됨
3) HTTP/1.1의 지속 커넥션
- HTTP/1.1에서는 keep-alive 커넥션을 지원하지 않는 대신, 설계가 더 개선된 지속 커넥션을 지원
- HTTP/1.0의 keep-alive와 달리, HTTP/1.1의 지속 커넥션은 기본으로 활성되어 있음; 별도 설정을 하지 않는 한, 모든 커넥션을 지속 커넥션으로 취급
- HTTP/1.1 애플리케이션은 트랜잭션이 끝난 다음 커넥션을 끊으려면
Connection: close헤더를 명시해야 함- 그러나 명시하지 않는다고 해서 영원히 커넥션이 유지되는 것은 아님. 서버/클라이언트가 언제든 끊을 수 있음.
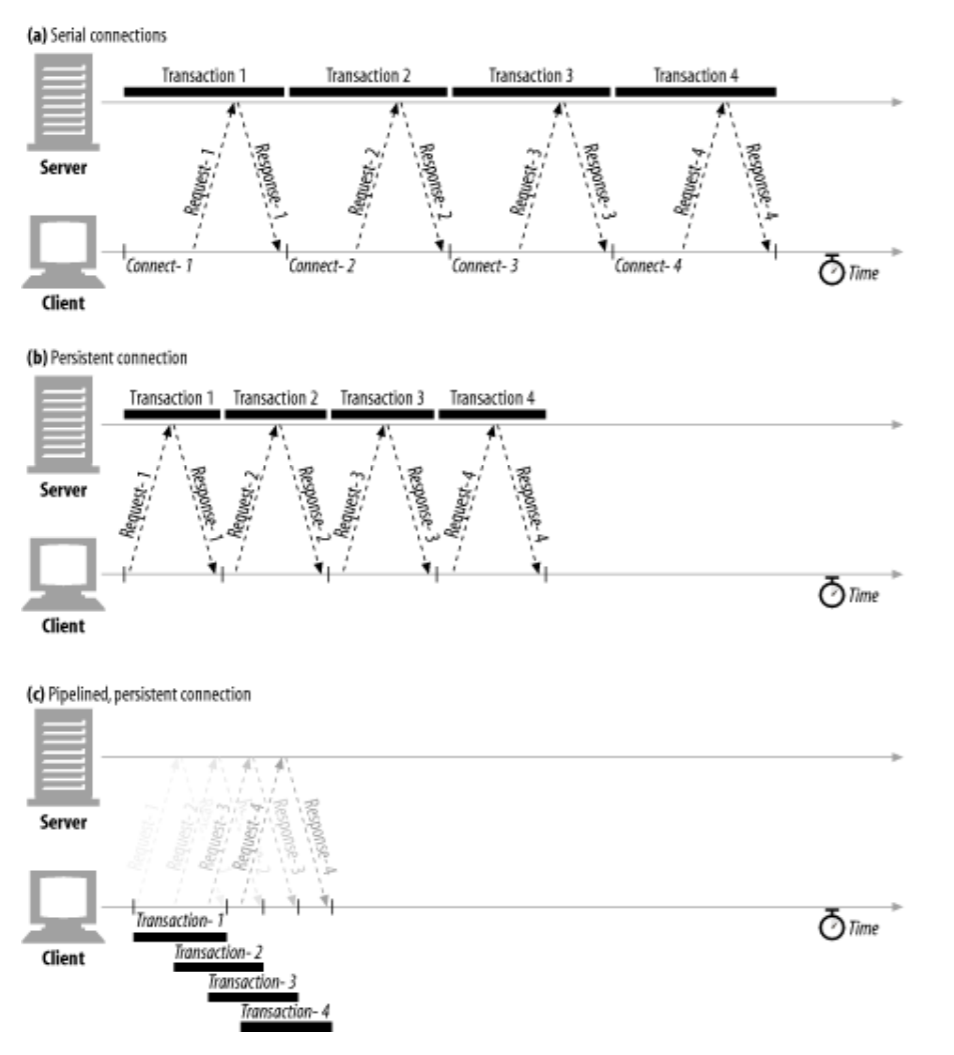
4) 파이프라인 커넥션
- HTTP/1.1은 지속 커넥션을 통해서 요청을 파이프라이닝 할 수 있음; keep-alive의 성능을 더 높여줌
4.7 커넥션 끊기에 대한 미스터리
- 커넥션 관리(특히 커넥션 끊기)에는 명확한 기준이 없음
- 보통 에러가 발생하면 끊기지만, 에러가 없더라도 언제든 끊을 수 있음
- 요청 데이터 전송 후 응답이 오기 전에 커넥션이 끊기면 서버에서 요청을 얼마나 처리했는지 전혀 알 수 없음
- 한 번 혹은 여러 번 실행됐는지에 상관 없이 같은 결과를 반환한다면, 그 트랜잭션은 멱등(idempotent)하다고 함
GET,HEAD,PUT,DELETE,TRACE,OPTIONS등은 멱등함- 그 외의 메서드는 파이프라인을 통해 요청하면 안 됨
우아한 커넥션 끊기
- 전체 끊기와 절반 끊기
- 애플리케이션은 TCP 입력 채널과 출력 채널 중 한 개만 끊거나 둘 다 끊을 수 있음
- 전체 끊기:
close()를 호출하여 TCP 커넥션의 입력 채널과 출력 채널의 커넥션을 모두 끊음 - 절반 끊기:
shutdown()을 호출하여 입력 채널이나 출력 채널 중에 하나를 개별적으로 끊음
- TCP 끊기와 리셋 에러
- 에러 발생을 예상하기 위해 ‘절반 끊기’를 사용해야 함
- 보통은 커넥션의 출력 채널을 끊는 것이 안전; 데이터 전송이 끝남과 동시에 커넥션을 끊었다는 것을 알게될 것이므로
- 클라이언트에서 더는 데이터를 보내지 않을 것임을 확신할 수 없는 이상, 커넥션의 입력 채널을 끊는 것은 위험
- 클라이언트가 이미 끊긴 입력 채널에 데이터를 전송하면
connection reset by peer메시지를 받고, 대부분의 운영체제에서 이를 심각한 에러로 취급하여 버퍼에 저장된, 아직 읽히지 않은 데이터를 모두 삭제함. 파이프라인 커넥션에서는 더욱 악화됨.
- 클라이언트가 이미 끊긴 입력 채널에 데이터를 전송하면
- 우아하게 커넥션 끊기
- 일반적으로 애플리케이션 자신의 출력 채널을 먼저 끊고 다른 쪽에 있는 기기의 출력 채널이 끊기는 것을 기다리는 것
- 안타깝게도 상대방이 절반 끊기를 구현했다는 보장이 없기 때문에 출력 채널에 절반 끊기를 한 후에도 데이터나 스트림의 끝을 식별하기 위해 입력 채널에 대해 상태 검사를 주기적으로 해야 함
- 만약 입력 채널이 특정 타임아웃 내 끊어지지 않으면, 애플리케이션은 리소스 보호를 위해 강제로 커넥션을 끊을 수도 있음
Subscribe via RSS